Do you want to pump up your service desk with a program that excites executives, provides great business value, and greatly lowers unplanned labor costs, incident volumes, and service outages? The 40-40-40 program targets a 40 percent reduction in incident counts, 40 percent reduction in resolution times, and a 40 percent increase in support staff skills for getting to root causes and eliminating the incidents they cause. This article describes how the program works and presents some examples from a large IT organization. You can use this approach in any IT organization.
One of the biggest headaches in any IT organization is that of unplanned labor.

One of the biggest headaches in any IT organization is that of unplanned labor. This is time spent by IT executives, managers, and support staff to deal with incidents and outages, rework, and recovery activities. In today’s DevOps world, this is called technical debt. It carries a price tag, typically $62.00 per hour on average for most IT organizations today. This cost doesn’t even include other costs such as project delays, poor customer satisfaction, penalties, and fines that are triggered when everyone has to drop what they are working on to deal with these unplanned issues. The main objective of the 40-40-40 program is to target these headaches with three key objectives:
-
Reduce Incidents. Proactively trend incidents and initiate actions to remove their underlying root causes, stopping incidents before users see them and reducing unplanned labor costs. list item
-
Reduce Incident Impact. For those incidents that can’t be readily removed, reduce times to initiate workarounds and resolutions, taking actions to minimize incident impact.
-
Increase Skill Sets. Upgrade service desk and support team analysis and problem solving skills to reduce the amount of labor spent on analyzing incidents and getting to root cause.
You can get your program going in seven steps.
Step 1: Ensure Reporting Is In Place for Incidents
Make sure you have adequate reporting in place that can provide basic metrics for incident counts (ideally by service, application/device, or support team), incident durations (typically from ticket creation to ticket resolution), and at least six months to one year of ticket history. These numbers should be presented in almost any IT incident management system. If not, your organization is operating blindly and probably has bigger issues than could be addressed by this program.
You will also need problem ticket logging and reporting capabilities as well as a Continual Service Improvement (CSI) register for logging and prioritizing resolution activities and their progress. Many IT service management systems provide these capabilities, but you can also handle these with spreadsheets if the capability doesn’t exist in your service management system.
Step 2: Determine Your Baseline Technical Debt
In this step, you will baseline your current unplanned labor costs. Here is an approach to do that with specific numbers taken from a real IT organization:
- Get the overall IT annual labor budget ($125M)
- Get the number of IT employees (1,100)
- Determine the average IT salary cost (A/B or $113,636)
- Estimate average hours worked in a year for IT employees (1,832 = an industry average)
- Calculate the IT hourly labor cost (C/D or $62)
- Get the incident ticket duration in hours for each incident ticket (from your reports)
- Apply a labor factor (percentage of ticket duration that incurred labor versus time the ticket was just sitting in a queue waiting—it’s okay to estimate—our example used 5 percent for all tickets)
- Calculate the ticket unplanned labor cost for each ticket (E-Hourly Rate * F-Ticket Duration * G-Labor Factor)
Step 3: Get Buy-In from Senior Executive Leadership
Put the results from Step 2 in a spreadsheet or reporting tool and present it to executive leadership. Here is an example of what was shown to senior executives in our example IT organization:
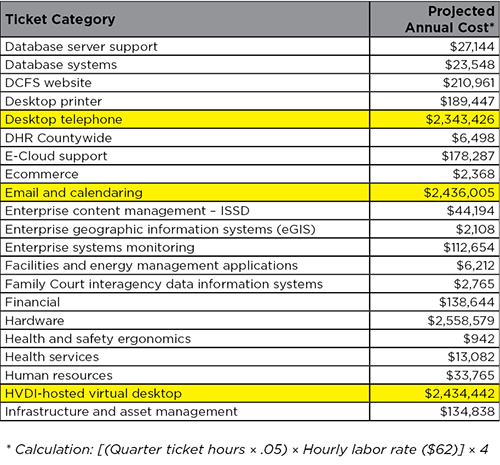
The projected annual cost was calculated as [Quarter Ticket Hours * 5% (0.05) * Hourly Labor Rate ($62)] * 4 (Quarters). Every dollar shown is wasted labor. Our example leadership did not like knowing that telephone incidents were costing them $2.3M a year, email issues $2.4M a year, etc. The goal of the program was to cut these costs by at least 40 percent across the board. These numbers helped us get buy-in from leadership to support the program, and the areas highlighted in the table were targeted to receive the most focus.
You can also highlight the unplanned labor portion of the IT budget. Simply total all the annual unplanned labor costs and divide by the IT annual labor budget. For example, if your IT organization spends $10M on labor and the unplanned labor adds up to $2M, then 20 percent of the IT budget is being wasted on technical debt activities—not a percentage many executives like to see!
It is also important that executive leadership be visible and seen as leading this program. This will set the proper tone for staff and management support of this initiative.
It is also important that executive leadership be visible and seen as leading this program.
Step 4: Train IT Staff and Management on Problem Management Core Concepts
For this step, establish a series of communication events to introduce and train staff on the program and problem management best practices. These events should include an overview of the 40-40-40 program, training on problem management processes and techniques, and a description of staff and management roles and responsibilities for the program.
Guidance and resources for problem management processes and techniques can be found in many places on the internet. The ITIL Service Operation book (The Stationery Office 2011) problem management chapter and third parties such as Kepner-Tregoe and others also come to mind.
Step 5: Arm Staff with Problem Management Techniques that Efficiently Get to Root Cause
As part of training, it also helps to establish a problem management toolkit as a support aid for IT staff and management. The toolkit is an inventory of different techniques that can be used to quickly control activities and drive down to root causes. A list of these techniques might include the following:
- 5 Whys
- Fault isolation
- Hypothesis testing
- Observation post
- Pareto analysis
- Kepner-Tregoe analysis
- Affinity mapping
- Chronological analysis
- Pain value analysis
- Fault tree analysis
- Trend analysis
- Causal loop analysis
- Service outage analysis
- Problem brainstorming
You can find information on any of these tools on the internet. The ITIL book chapter mentioned earlier also describes many of these tools and techniques.
The table below lists the techniques mentioned above and situations where you’d want to use them:
| Problem Situation | Suggested Analysis Techniques
|
|---|
| Complex problems where a sequence of events needs to be assembled to determine exactly what happened |
Chronological analysis
Technical observation post
|
| Uncertainty over which problems should be addressed first |
Pain value analysis
Brainstorming |
| Uncertain whether a presented root cause is truly the root cause |
5 Whys
Hypothesis testing
|
| Intermittent problems that appear to come and go and cannot be recreated or repeated in a test environment |
Technical observation post
Kepner-Tregoe
Hypothesis testing
Brainstorming
|
| Uncertainty over where to start for problems that appear to have multiple causes |
Pareto analysis
Kepner-Tregoe
Ishikawa diagrams
Brainstorming
|
| Struggling to identify the exact point of failure for a problem |
Fault isolation
Ishikawa diagrams
Kepner-Tregoe
Affinity mapping
Brainstorming
|
Uncertain where to start when trying to find root cause 5 Whys
|
Kepner-Tregoe
Brainstorming
Affinity mapping |
As a starting point, focus on the 5 Whys. This technique is very simple but also very easy to use and effective. The steps are:
- Describe what took place
- Ask “Why?”
- Listen to answer given
- Ask “Why?” again
- Repeat steps 2 through 4 until root cause is identified
Step 6: Instruct Staff to Proactively Raise Problem Tickets and Monitor Their Progress
At this point, have IT staff, management, and support teams undertake activities to proactively identify root causes and activities to reduce incidents and their duration. Think about some key considerations when undertaking this effort.
Look for low-hanging fruit. Don’t spend a lot of time identifying actions that yield little reduction. However, tiny efforts and no-brainers should be noted as many of these done in aggregate might yield significant savings.
Focus on outcomes. Every reduction opportunity proposed must provide an estimate of how many tickets will be avoided and an estimate for unplanned labor cost savings (using the approaches described in Step 2).
Document the cost saving opportunities from Step 2. These will be used to confirm and prioritize everyone’s actions (see Step 7; findings may show that many teams might need to be involved to implement the improvements).
Recognize that root causes may not always be technical. Lack of skills, training, communication, no ownership, and poor vendor support may also be root causes.
Consider key program roles and activities to undertake from a program perspective.
| Program Role | Key Program Activities |
|---|
| Problem Manager |
• Owns the program
• Trains support staff
• Assists in identifying problems, root causes, and action items
• Coordinates cross-service issues
• Coordinates how activities will be prioritized
• Monitors progress on actions being implemented
• Monitors support team compliance to the program
|
| Service Owners and Support Team Managers (including the Service Desk) |
• Reviews data for their service or support team
• Identifies problems and known errors
• Identifies options and actions to undertake to remove those errors
|
| Service Manager, Continual Service Improvement Manager, or Project Office |
• Assists with business cases
• Puts actions on CSI register
• Assists with prioritizing actions to be taken
• Monitors the register to make sure actions are being implemented |
Step 7: Log, Prioritize, and Implement Actions to Resolve Problems or Reduce Their Impact
A register should be maintained as each team identifies improvement actions. Actions get logged into the register along with their estimated cost-saving opportunities. The problem manager then coordinates agreement across IT to prioritize which actions will take place. Hold a monthly meeting to do this as well as review the progress of any actions agreed to in previous meetings. At a minimum, the CSI register should contain the following:
- ID number to quickly reference the action (e.g., X001)
- A brief title or description of the action (e.g., Fix Application XYZ user lockouts
- A detailed description (e.g., Remove duplicate Active Directory entries to avoid access errors on…)
- Effort estimate (e.g., 1 month, 3 months, 9 months, etc.)
- Savings estimate (e.g., $40–60K)
The problem manager and key stakeholders review the register to prioritize and identify action items to be undertaken. Those that are approved are then assigned to support teams and service owners for implementation.
To communicate program activities to key stakeholders and executives, the chart below presents one way of summarizing what the program is undertaking.

At a minimum, the program should provide communications on a monthly basis showing business based outcomes such as lower costs and incident counts.
On an ongoing basis, the problem manager also monitors compliance to the program. This can be done by looking at the incident counts for each support team or service and comparing that against things like number of problem tickets raised, total cost savings identified, and implementation assignments. The bottom line is to make sure each team or service is proactively working to improve things and not just being reactive.
As a final note, the table below identifies challenges you may run into with this program and what you might do about them:
| Challenge or Risk | Suggested Mitigation |
|---|
| Staff struggles to find root causes |
Consider stronger use of problem management toolkit techniques
|
| Not enough time to proactively find problems |
Time box efforts (e.g., commit to two hours per week to focus solely on problems or assign a resource part time)
|
| Staff is unsure how problem processes might work |
Contact problem management team for guidance |
| Service supported is problematic and has many issues |
Focus on improvements prioritizing which problems provide the greatest bang for the effort and whittle away in small chunks
|
| Too many escalations from service desk for similar issues and incidents |
Make sure you publish known errors allowing the service desk to better resolve issues independently
|
| Can’t always determine the business impact of outages |
Start to check the CMDB, ticket documentation, or prior instances of the issue
|
| IT doesn’t want to fund implementation activities |
Rely on known error and workarounds but keep improvement actions logged in the CSI register with their cost opportunities |
Randy Steinberg has years of hands-on operations experience gained from many clients around the world. He recently authored the new ITIL Service Operation book. He was global head of service management for a worldwide media company with 176 operating centers around the globe and had one client that won a Malcolm Baldrige award for the quality of their IT services. Readers interested in gaining free access to ITSMLib, which is a large repository of IT service management documents and artifacts, can send email to Randy at [email protected] for access.