Date Published August 31, 2018 - Last Updated December 13, 2018
What is ticket categorization, and why is it so important to the success of a support center? Ticket categorization is a component of several support center processes, namely event management, incident management, problem management, and request fulfillment. When an event/incident/request/problem is identified, it should be logged to be captured, then classified/categorized in accordance with a scheme or table so that the nature of the issue can be determined and the proper next steps taken to handle the issue.
Since categorization is an integral component of all four of these service operation processes, according to ITSM/ITIL® best practices, these processes should all use the same category scheme to facilitate process integration and the effective handling of issues detected.
To illustrate, an event detected by a monitoring tool might trigger the opening of an incident, which in turn is justification for a problem to be registered with problem management so that the root cause can be discovered. In this case, a common classification of the issues is used by all three processes. It’s important to realize that categorization takes places as a specific step in each of these processes. For example, categorization during incident management occurs following the logging step but before the prioritization step.
The ITIL Service Operation volume provides general guidelines on planning for proper categorization during the incident management process (as well as other processes). It suggests that a scheme/table be used and that multiple levels of classification be implemented in order to specifically define the type of issue being logged. Your support center’s Standard Operating Procedure (SOP) ought to refer to your categorization process and scheme, and of course your automated tools (monitoring tools, ticketing system) should support the scheme and automate it with dropdowns/prompting once agreed on and defined.
An Opportunity for Improvement
The ticket categorization scheme is an opportunity for improvement for most support centers. Unfortunately, many support center managers rely on the automated ticket system tool, or monitoring tools, and assume that the tool will automatically classify the issues correctly. But, sadly, this is not the case. Although most ticketing systems do have a built-in scheme/table for classifying incidents/requests, the table must be set up and tailored to your particular support environment.
Relying on default classification settings in an automated ticketing system will result in poor or no classification of issues reporting, longer average handle times, slower resolution to issues, incorrect escalation to other groups (should that be needed), and poor-quality reporting of the issues the support center is dealing with.
Relying on default classification settings in an automated ticketing system will result in poor-quality reporting of the issues the support center is dealing with.

Support center managers must realize that an effective ticket categorization scheme drives three key areas of performance:
-
Correct escalations to other support groups, so that if the issue isn’t resolved at the first level support desk, the issue can be accurately assigned to the correct second line or tier 2 support team
- The effectiveness and speed of your searching and matching process, so that your first line analysts will be able to maximize resolution at tier 1, without escalation to other support teams
- The quality and effectiveness of daily, weekly, and monthly support center performance reporting, so that you know what types of issues are being dealt with, can perform effective trend analysis, and further optimize support center performance
The Role of Categorization in Process Integration and Performance
Having a common categorization scheme shared by all the service operation processes can be very beneficial. For example, when an event is detected by an automated system monitoring tool, if the event management process is using that same scheme, the process can classify the event in accordance with the same rules—and even automatically trigger an incident based on that event (should that be called for).
Problem management is another operational process that is closely related to incident management, but instead deals with finding the “root cause” of issues and eliminating them from the infrastructure and applications—so that incidents are prevented and don’t recur. To accomplish its mission, problem management must carry out both reactive and proactive activities. Reactively, it must log problem reports that are linked to incidents, and in doing so, categorize these in the same way as the associated incidents. Using the same category scheme helps problem management correlate incoming problem tickets with the incidents that are triggering these problems.
Problem management also carries out proactive activities, an example being trend analysis of incidents being logged and handled over time. To analyze the types of incidents, a shared categorization scheme must be in place so that the various types of incidents are evident in trend reports, and problem management can proactively identify any underlying problems not yet formally reported.
Request fulfillment also relies on a shared categorization scheme. When an issue has been identified, it needs to be first classed either as an incident or a service request. Incidents are then handled according to the incident management process, and issues identified as service requests are passed to the request fulfillment process for further handling.
Approaches to a Categorization Scheme
A good practice is to formulate a multi-level category scheme, usually with four levels of categorization (from hi-level to lower-level). One or two levels is usually not sufficient to get a fine enough definition of the issue, and five or six levels of categorization is normally not required (and will take much longer for the issue to be classified).
The table or scheme is usually organized from general to specific, from hi-level to lower level, as in these examples:
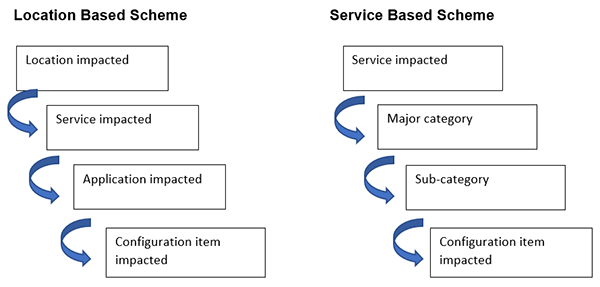
There is no one categorization scheme that fits all support center environments. Since some centers are distributed, location matters, and they might determine that the location affected is the top level of the scheme. Other support centers that are centralized might determine that the service impacted is the first characteristic to classify, then proceed from there.
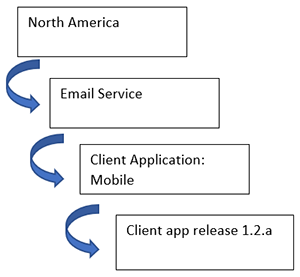
Once the top level is determined, then a major and minor category usually form and then two levels of detail. These could be the service impacted and the type of component of the service—for example, the application, or a particular supporting service (like a database service, network service storage service, etc.). The most specific category lower level classification is normally the individual Configuration Item (CI) that is being affected by the event/incident/request or problem. Using the location-based scheme, we might have an issue reported that is categorized as in the example pictured.
Planning and Implementing an Effective Categorization Scheme
Many support centers just jump right in, using a spreadsheet created by some other support center. While this is one way to start, we don’t recommend stopping there. Yes, gather examples of what other support centers in your industry are using, but follow the HDI and ITIL® guidelines for setting up an effective categorization scheme. Then you will more likely meet with success in the areas mentioned earlier!
Here are the general steps to follow (based on the steps outlined in the ITIL Service Operation volume, sect 4.2.5.3.) to create/improve your categorization scheme:
-
Assess the scheme you have in place now (if indeed you have one), and do a performance baseline on the effectiveness of the current scheme. How accurate are the escalations to other groups? What is the average speed of resolution? How long on average does it take to classify an issue? Is reporting being compromised by poor classification? This will inform you about the extent of the changes required; what’s more, you will be able to measure the impact after you design and implement the new, improved scheme.
-
Hold a brainstorming session with other tier 2 and 3 support groups to assess the quality of the current scheme and how best to improve it. You get better quality knowledge and diverse perspectives by consulting with all support groups, and you receive that all-important buy-in with other groups, as they will have to follow the same scheme. Also involve the event, incident, problem, and request fulfillment managers for their input.
-
Arrive at the initial/improved four-part scheme. This will usually start with a top level (location/service), major category, then sub-category, and then the configuration item. There is no one right answer here, but most schemes have four levels. Too many levels make it too complex and too few defeats effectiveness. Include an "Other" category, and then focus on continually minimizing any issues that fall into this bucket!
-
Test this initial/improved scheme during a short trial period, with a subset of issues, to assess the categorization process and scheme in terms of its effectiveness (in minimizing improper escalations, speeding search and match, and in providing sufficient level of detail for reporting).
-
After the trial period, perform an analysis of the issues logged and classified using the test scheme. How are the incidents/requests being distributed across the scheme? Do the major and minor categories make sense? How about the lower level categories? Are too many issues falling into the “Other” category bucket?
-
Use the results of your analysis to fine tune the categorization scheme, and then run another test to confirm its effectiveness before putting into production. Make sure you orient all support groups to the new/improved scheme through a short training session/webcast.
Note: Don’t forget to update your event, incident, request fulfillment, and problem management SOPs, so that your process documentation reflects the new category scheme being used and supported by your ticketing tool.
Validating and Checking for Success
Once you have the new scheme in place, you should see a marked improvement in performance after a few months. Do another baseline performance assessment to gauge the impact of your improved categorization scheme. If the implementation process was performed effectively, and the update to the scheme was done right, you should see:
-
Improved speed of searching and matching. Tier 1 support will be able to locate a workaround or a solution much more quickly, which in turn will facilitate faster overall speed of incident resolution and request handling.
-
Improved accuracy of escalations to other support groups (you should see fewer bounced back escalations to tier 1). This will improve the average speed of resolution, as issues won’t be bouncing around between groups.
-
Improved accuracy in reporting and better trend analysis, which means that you will have a clearer picture of where most of the issues are happening. As a result, problem management will be able to focus prevention efforts on the categories of incidents and requests that are the biggest offenders.
The improved categorization scheme will have significant benefits to the support center and to the IT service provider organization as a whole. Overall costs should be favorably impacted, performance will improve, and customer and user satisfaction should benefit as well.
Once your scheme is in place, be sure to do a periodic review of the scheme. Ensure that new products and services are factored into the scheme, so that it can remain relevant and effective.
ITIL® is a registered trademark of AXELOS, Limited. All rights reserved.
 Paul is the president and principal consultant of Optimal Connections LLC. With more than 30 years of experience in planning and managing technology services, Paul has held numerous positions in both support and management for companies such as Motorola, FileNet, and QAD. He is also experienced in service desk infrastructure development, support center consolidation, deployment of web portals and knowledge management systems, as well as service marketing strategy and activities. Currently Paul delivers a variety of services to IT organizations, including Support Center Analyst and Manager training, ITIL Foundation and Intermediate level training, Best-Practice Assessments, Support Center Audits, and general IT consulting. His degrees include a BA and an MBA. Paul is certified in most ITIL Intermediate levels and is a certified ITIL Expert. He is also on the HDI Faculty and trains for ITpreneurs, Global Knowledge, Phoenix TS, and other training organizations. For more about Paul, please visit www.optimalconnections.com.
Paul is the president and principal consultant of Optimal Connections LLC. With more than 30 years of experience in planning and managing technology services, Paul has held numerous positions in both support and management for companies such as Motorola, FileNet, and QAD. He is also experienced in service desk infrastructure development, support center consolidation, deployment of web portals and knowledge management systems, as well as service marketing strategy and activities. Currently Paul delivers a variety of services to IT organizations, including Support Center Analyst and Manager training, ITIL Foundation and Intermediate level training, Best-Practice Assessments, Support Center Audits, and general IT consulting. His degrees include a BA and an MBA. Paul is certified in most ITIL Intermediate levels and is a certified ITIL Expert. He is also on the HDI Faculty and trains for ITpreneurs, Global Knowledge, Phoenix TS, and other training organizations. For more about Paul, please visit www.optimalconnections.com.