Date Published November 3, 2022 - Last Updated January 20, 2023
When it comes to IT support, promptness is the main thing that makes people happy. Unfortunately, it is also one of IT support’s biggest problems.
Being busy certainly doesn’t help. It’s not the main issue, though. Backlogs are the result of operational shortcomings which represent gaps in standard practice, including particularly weak prioritization and teamwork.
Ideally, practice gaps would be filled through service tool utilization, so that teams are guided to reliably meet needs and expectations. The less effective alternative is to continuously nurture good practice principles upon which “infill” practices are based in order to bring out desirable attitudes and behaviors.
The principled approach cannot get very far without some degree of practice advancement, however. IT support is complex, so it is necessary to have information, surfaced by effective processes and presented well, to make sense of it all.
The shortcomings intrinsic to standard practice cause many common operational issues.Twelve of the issues affect promptness, caused largely by ineffective prioritization and teamwork. They are:
- Assignment of service tickets to inefficient and vulnerable ticket queue silos.
- Lack of collaboration and teamwork, especially between different teams; bouncing tickets around slows things down.
- Expectations management.
- First contact resolution rate/capability isn’t maximized.
- Service Desks must be "high velocity", but flow of activity (performance) is sometimes weak or unsteady.
- Activity prioritization - the question of "what next?"
- Backlog control and ticket abandonment.
- Premature ticket closure (after abandonment, most prevalent when a requester doesn’t reply to an emailed question, but the support team does not chase the requester).
- Weak manageability due to rudimentary metrics; there is limited actionable operational insight for “exception management”, for example to know when a ticket has been sat with no progression for too long.
- Customer updates are sometimes not seen or quickly responded to.
- Missed appointments and failure to meet commitments.
- Ticket assignment mistakes made by service desk inductees.
There are another nine common operational issues affecting IT support service management.
The realization is that IT Support is difficult to do well.
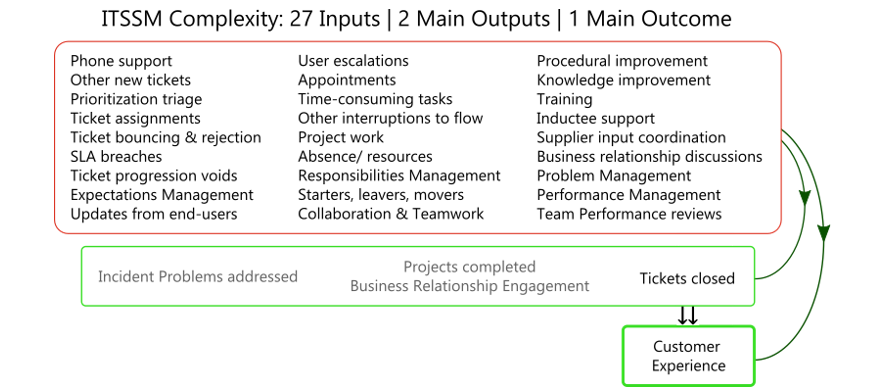
This conclusion becomes even stronger when looking closely at the complexity. Apart from the fact that many different support needs must be handled every day by staff with differing levels of knowledge, many inputs must be balanced and checked to produce as few as one output and one outcome:
The first of twenty good practice principles: “Be attentive”
Context is everything. IT organizations who are not busy or stretched will find it easy to keep support workload in check. Basic approaches will work just fine.
But for most, being busy means that team members naturally get caught up in the here and now, probably for much of the day.
For a frontline service desk, the “here and now” is first-response activity, spent on the phone and plowing through other new tickets and interactions. When looking at the ITSSM Complexity illustration above, however, you can pick out many other inputs that add to what must be done straight away, or as soon as possible.
The problem is that many service tickets are not completed straight off in the here and now, so it is necessary to find time to return to them before too long. Easier said than done? Being busy, plus being unguided due to process shortcomings, means that indeed, this is so often the case.
Examples of process shortcomings:
- Use of on-hold puts “the ball in the other court”, so on-hold tickets naturally take the lowest of priority, making abandonment more likely.
- IT organizations do not often implement “auto chase-down to closure” (progression automation) for tickets that are “with user” for their response.
- Due to other operational shortcomings, “progression triggers” such as user updates, and chase escalations, often do not have the necessary effect (they do not trigger progression), so requesters feel ignored.
- When ticket queues are extensive, it is difficult to know how to prioritize one ticket ahead of another, especially when SLA’s have breached, and many tickets are on hold.
- When a colleague is on leave or is otherwise not available to provide support for a considerable period, their tickets might not be covered.
The thing that is missing is focus - focus on the various inputs when needed. To be attentive is to focus on all the things that need to be done. Ideally, attentive service from a team will abridge ticket ownership silos because a support team’s purpose is to meet recipient needs and expectations, period. “Control-by-role” can help enormously to this end.
In my next article, I will explain the tool-formed, process-based approach to being attentive.
David Stewart is the author of TOFT – 12 tool-based practices that fill Incident and Request Management gaps.