This post is part 2 of a four-part series by Adam Krob and Bill Stockton. See Adam Krob’s Part 1. The content assumes a modicum of familiarity with ITIL® and the vocabulary set out within those libraries.
“Do you wonder,” asked a woman the other day during a discussion on problem management, “whether we all have an Alice within us?” My confusion warred with her amused expression before she added, “Shortly after she disappeared down the Rabbit Hole…”
Ah, yes. Alice in Wonderland—and what a perfect visual. Shortly after she falls down the Rabbit Hole, Alice, on seeing her body change, tries to rationalize her way through her predicament:
“… how puzzling it all is! I'll try if I know all the things I used to know. Let me see: four times five is twelve, and four times six is thirteen, and four times seven is—oh dear! I shall never get to twenty at that rate! However, the Multiplication Table doesn't signify: let's try Geography. London is the capital of Paris, and Paris is the capital of Rome, and Rome—no, that's all wrong, I'm certain!”
How symptomatic of many organizations who like to put issues in buckets and try to count them. They struggle and fail to eliminate repeat issues faced by customers and support because they fail to capture required information leading them astray and further down that rabbit hole.
Taxonomy Down a Rabbit Hole
We’re left with the question, “How do organizations typically approach ITIL Problem Management?” The answer lies in just one word: Taxonomy.
Much like Alice trying to force her problem into a classification system, organizations typically build taxonomies when adopting a new tool to support ITIL and knowledge management practices. Rather like a Standard Operating Procedure, we follow a series of steps:
- We build classification systems that help staff responsible for incident management
- Those systems route issues as quickly as possible to the resolver (right person at the right time)
- The systems help account for the need to report and offer metrics.
Ultimately the reports and metrics aren’t intended to serve incident management. Rather these are a nod to problem management; we want to be able to report on how many issues are occurring of a certain type.
A Quick Look at Triggers
There are four primary ITIL problem management triggers; organizations already devote enough attention to the first two, given their nature. Later, we will look at two triggers: High Frequency and Cumulative Duration.
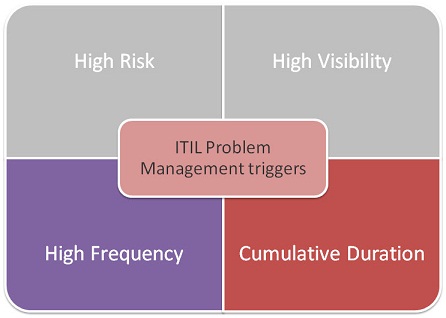
Let’s briefly review each of these four triggers:

If It Isn’t Broken, Why Fix It?
For problem management, we have a different problem. The way we typically classify incidents also isn’t practical for problem management. To achieve our objectives in problem management, the classification system would have to extend to a unique resolution and/or root cause for every incident. Essentially taxonomy of this type leads us down too many rabbit holes. (And they can be very difficult to get out….) This leads to:
- Many tiers of categories, sub-categories, sub-sub categories, sub-sub-sub categories, etc.
- Very long drop down lists.
Not only is this impractical for use by support staff solving incidents, it is also very difficult to maintain. Organizations derive reports on the most frequently occurring incidents with the most frequently occurring combination of classification fields—only to find on analysis that the incidents in the report are not all the same. There are multiple resolutions and root causes at work.
The way we typically classify incidents isn’t practical for problem management.

The Incident-al Perspective
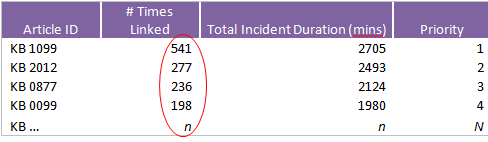
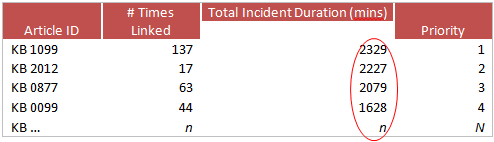
So, if we aren’t using the incident classification data to prioritize our problem management candidates, where do we turn? We report on the most frequently used knowledge articles (linked to the most frequently occurring incidents) and the knowledge articles linked to the incidents that due to frequency take the most cumulative time to resolve (cumulative duration). The following charts illustrate these types of articles/incidents.
High Frequency:
Cumulative Duration:
A Better Way to Prioritize
One might ask, “Is reporting against knowledge article usage (as evidenced by linking articles to incidents) a better way to prioritize incident types for problem management?”
The answer will always be, “Yes.”
Each knowledge article relates to a unique incident root cause or resolution actions (in the case of a workaround). The article makes explicit what the symptoms are behind the issue linked to that article, the conditions under which the issue occurs, the actions taken to understand and ultimately resolve the issue, and the various environment details attendant with a particular issue (software version, hardware, etc.).
The specificity is more precise than we achieve with (a reasonable and achieve-able) taxonomy and acts as a mini-specification for the engineering/R&D teams tasked with remediating the issue via automation, bug-fix, or self-service.
The information gathered as a result arms us. It helps us prioritize issues requiring attention from the engineering/R&D function and, more importantly, demonstrates the value of the support function to them. It stops processes disappearing down rabbit holes.
Your comments and challenges are welcome.
Bill Stockton brings more than two decades of international experience in the financial services industry to his role as a senior advisor at The Verghis Group, Inc. Prior to joining The Verghis Group, Bill had a distinguished career at Deutsche Bank, where he managed business-critical, globally deployed, complex application support. His innovative approach and alignment of resources across the organization helped project leaders and support managers successfully adopt and implement a knowledge management process for over 7,000 support staff around the world. Keenly interested in ensuring change “sticks” when a company evolves into a knowledge-sharing organization, Bill works closely with clients to develop and translate strategies into specific goals, tactics, and deliverables to achieve the desired results. His current areas of research include call recording and customer satisfaction, recruitment and interviewing, and searching for knowledge. Bill received his BS in psychology from the University of North Carolina at Chapel Hill. He also completed the executive education and leadership program at the London Business School. He is a member of the Microfinance Club of New York, and he tutors kids in the JCCA Two Together Tutoring program. In addition, Bill is a founding curator of the startup DancingE and its new knowledge-sharing practices and community product called klever. Follow Bill on Twitter
@Bill_Stockton
.