Date Published September 2, 2020 - Last Updated December 10, 2020
This is the second part of a three-part series focusing on the agility of being able to operate remotely or from home locations in lieu of expensive hot sites or when local issues affect on-site operation. This article looks at applying what we learned about business continuity from COVID-19 but applies it to a long-term continuity strategy for service and support organizations focusing on making it possible for technology teams to operate remotely, focusing on operations, application development teams, technology, and technology support teams.
“Hands On” Operational Support
While many organizations are already fully virtualized and remote, others have not yet invested in the tools and expertise needed to achieve lights-out or virtual operations. Their legacy continuity plans may still be old-school re-location of the data center in the event of an issue, but that approach is not as effective for high availability of services and adds significant cost. The limitations include:
- Difficulty maintaining operations in the event of a weather emergency or epidemic/pandemic conditions
- Need and expense of keeping people on staff 24x7 to manage incidents and outages
- Delays in addressing operational issues when technical or application teams need to get to the data center to investigate or resolve an issue
- Expense of relocating people and services to an off-site facility
- Lack of ability to fail over to a live backup data center if a service cannot be restored within service levels
Many organizations have not yet invested in the tools and expertise needed to achieve lights-out or virtual operations.

Enabling Remote Tech Teams
In the context of this article, “fully virtualized” refers to the creation of a virtual data center environment by using several smaller data centers that share the full burden and capacity needed for operations. If a data center is disabled/destroyed, the other(s) pick up the load until service is resumed. This type of environment offers increased resilience and is more permanent than paying to maintain a hot-site that may never be used.
A fully virtualized environment can also be established by combining internal data centers with third-party data centers or cloud services.
Why is this virtual data center approach beneficial?
- Greater resilience means higher service availability every day. It may be possible to eliminate all downtime due to instant fail-over.
- Moving to a fully virtual, lights-out operation leverages technology that makes fully remote support possible, lowering daily operating costs by alerting responsible parties vs. having people working 24x7.
- Weather and other natural disasters, epidemics, and the like cannot take out operations as staff can work from home with no change in how they work (technically, of course).
A remote approach has many of the benefits of the fully virtual data center approach except the resiliency of not needing a hot site and disaster recovery program. It can still offer the benefit of enabling staff to work remotely when a weather, natural disaster, or medical event occurs. It also may be considered the first step towards expanding to a virtual data center approach.
Getting There
Consider leveraging a crawl, walk, run approach to a full virtual data center operation:
-
CRAWL: implement technology to go fully remote
-
WALK: enable staff to work from home one to a few days per week to get them ready to manage in the new environment
-
RUN: add data centers or outsource to data center providers and move to a fully virtual data center approach
This will obviously take planning and funding, so consider the following approach:
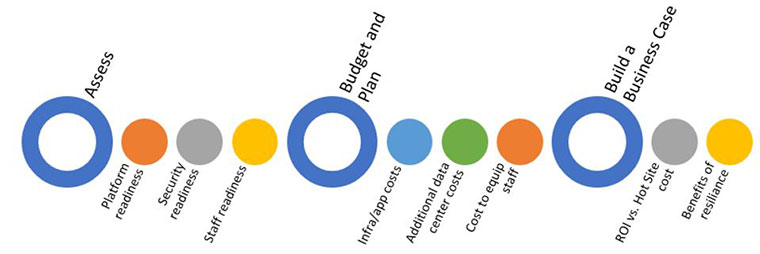
Step 1: Assess Your Readiness
- Can your platforms support remote operations? What would it take to get them there? Consider adding robotics for areas that require a human on premises, like mounting drives or tapes for legacy systems.
- Will security get in your way? Are some systems or applications only able to be accessed from internal networks? Add remote technology to provide access and train staff to use it.
- Does any staff need training in new ways of working? If so, include training in the plan.
Step 2: Plan the Initiative and Determine the Costs
- Consider all application, technology, and training costs needed for each phase of the project.
- Put together a detailed plan and budget that includes any professional services needed for the entire Crawl-Walk-Run journey.
Step 3: Build a Business Case
- Look at the current budget for business continuity, including hot/cold site costs, insurance contracts, and the cost to move operations in the event of a disaster.
- Align potential savings with the program phases, and remember to include savings associated through eliminating downtime.
Once the business case is ready, it’s time to secure the funding and go!
Phyllis Drucker is an ITIL® certified consultant and information leader at Linium, a Ness Digital Engineering Company. Phyllis has more than 20 years of experience in the disciplines and frameworks of IT service management, as both a practitioner and consultant. She has served HDI since 1997 and itSMF USA since 2004 in a variety of capacities including speaker, writer, local group leader, board member, and operations director. Since 1997, Phyllis has helped to advance the profession of ITSM leaders and practitioners worldwide by providing her experience and insight on a wide variety of ITSM topics through presentations, whitepapers, and articles and now her new book on the service request catalog, Online Service Management: Creating a Successful Service Request Catalogue (International Best Practice). Follow Phyllis on Twitter @msitsm.